数据结构的分类
常见的数据结构包括数组、链表、栈、队列、哈希表、树、堆、图,它们可以从逻辑结构和物理结构两个维度进行分类。
逻辑结构:线性与非线性
逻辑结构主要描述的是数据元素之间的逻辑关系,它可以分为线性和非线性两大类。简言之,线性结构指数据在逻辑关系上呈线性排列,非线性结构则呈非线性排列。
- 线性数据结构:数组、链表、栈、队列、哈希表,元素之间是一对一的顺序关系。
- 非线性数据结构:树、堆、图、哈希表。
非线性结构又可以进一步分为树形结构和网状结构: - 树形结构:树、堆、哈希表、元素之间一对多的关系
- 网状结构:图,元素之间是多对多的关系
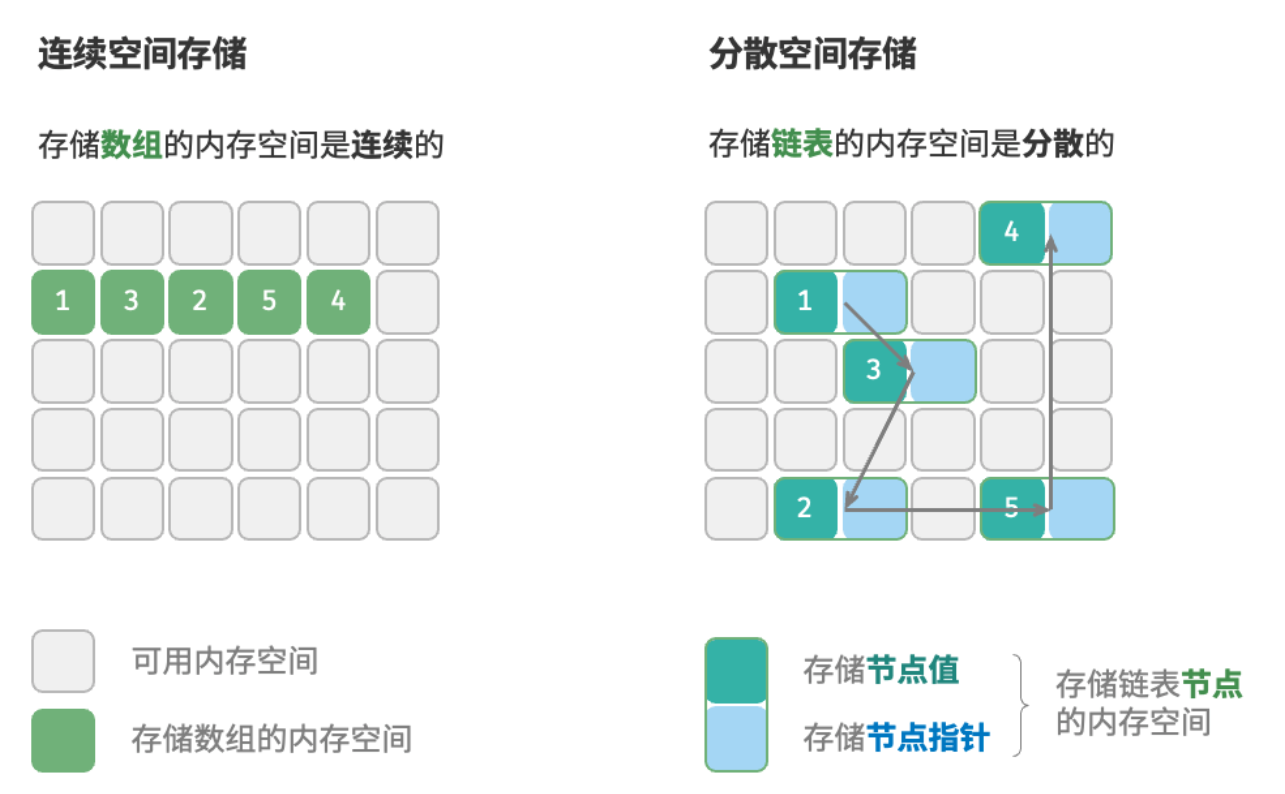
物理结构:连续和分散
物理结构反映了数据在计算机内存中的存储方式。可分为连续空间存储(数组)和分散空间存储(链表)。物理结构从底层决定了数据的访问、更新、增删等操作方法,两种物理结构在时间效率和空间效率方面呈现出互补的特点。
需要注意的是,所有的数据结构都是基于数组、链表或者二者的组合实现的:
- 基于数组可实现:栈、队列、哈希表、树、堆、图、矩阵、张量(维度> =3的数组)等。
- 基于链表可实现:栈、队列、哈希表、树、堆、图等。
基本数据类型
我们日常了解到的文本、图片、视频、语音、3D模型等格式的数据,基本都是由各种基本数据类型组构成。
什么是基本数据类型
通常而言,基本数据类型是CPU可以直接进行运算的类型,或者在算法中直接被使用的类型,主要包括以下几种:
- 整数类型
byte、short、int、long - 浮点数类型
float、double,用于表示小数。 - 字符类型
char,用于表示各种语言的字母、标点符号甚至表情符号等。 - 布尔类型
bool,用于表示“是”与“否”判断。
基本数据类型以二进制的形式存储在计算机中,一个二进制位即为1bit,在绝大多操作系统中, 1字节(byte)由 8比特(bit)组成。
基本数据类型与数据结构的关系
基本数据类型提供了数据的“内容类型”,而数据结构提供了数据的“组织方式”。
1 | # 使用多种基本数据类型来初始化数组 |
数字编码
原码、反码和补码
数字是以“补码”的形式存储在计算机中。
- 原码:将数字的二进制表示的最高位视为符号位,其中0表示正数,1表示负数,其余位表示数字的值。
- 反码:正数的反码与其原码相同,负数的反码是对其原码除符号位外的所有位取反。
- 补码:正数的补码与其原码相同,负数的补码是在其反码的基础上加1。
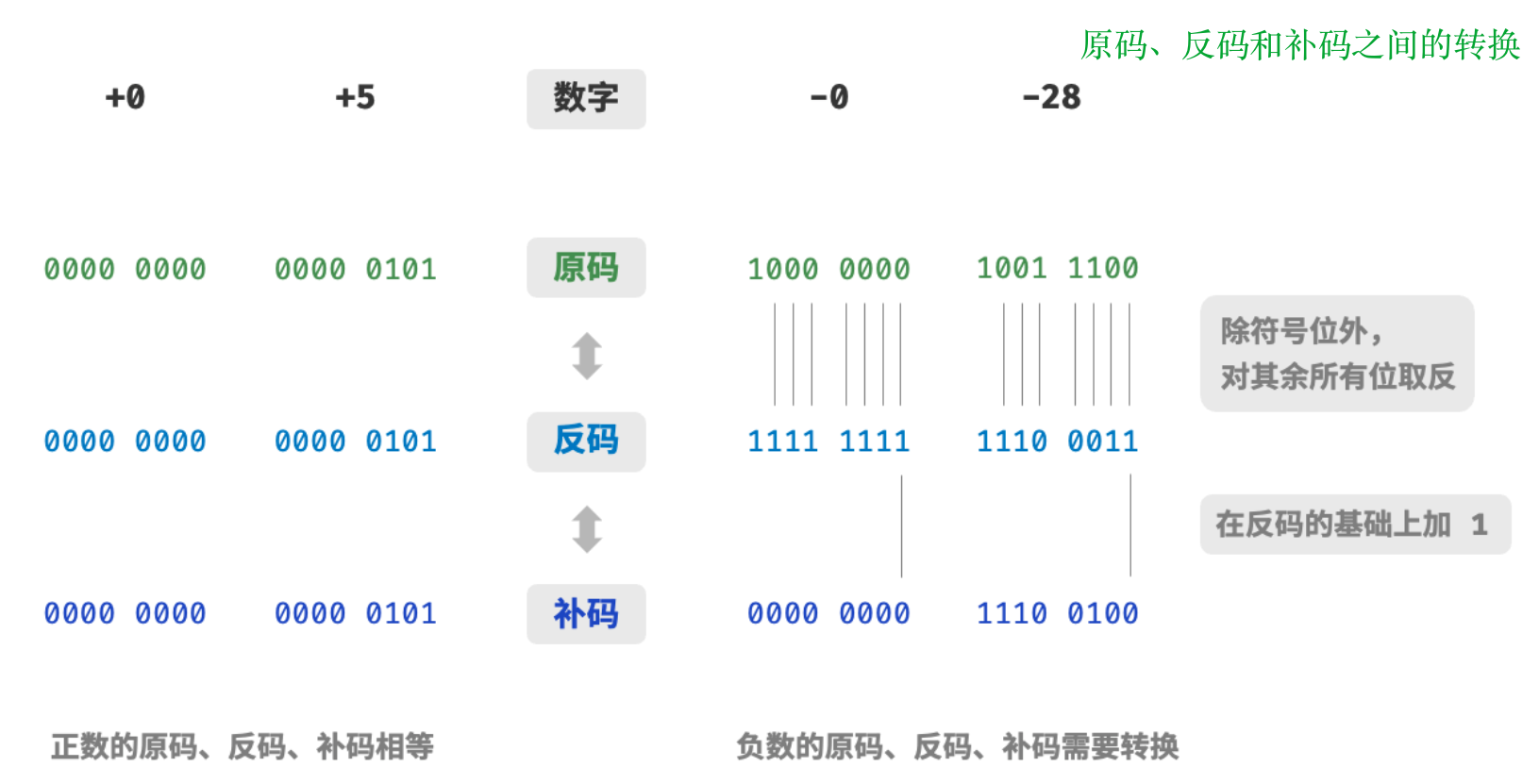
需要注意的是:
- 引入反码是为了解决负数不能直接用于用算。
- 引入补码是为了解决原码和反码都有正负零歧义问题。
浮点数编码
为什么int和float长度都是4字节,但float取值范围远大于int?
因为float采用了不同的表示方式,根据 IEEE 754 标准,32-bit 长度的 float 由以下三个部分构成:
- 符号位S:占1位
- 指数位E:占8位
- 分数位N:占23位
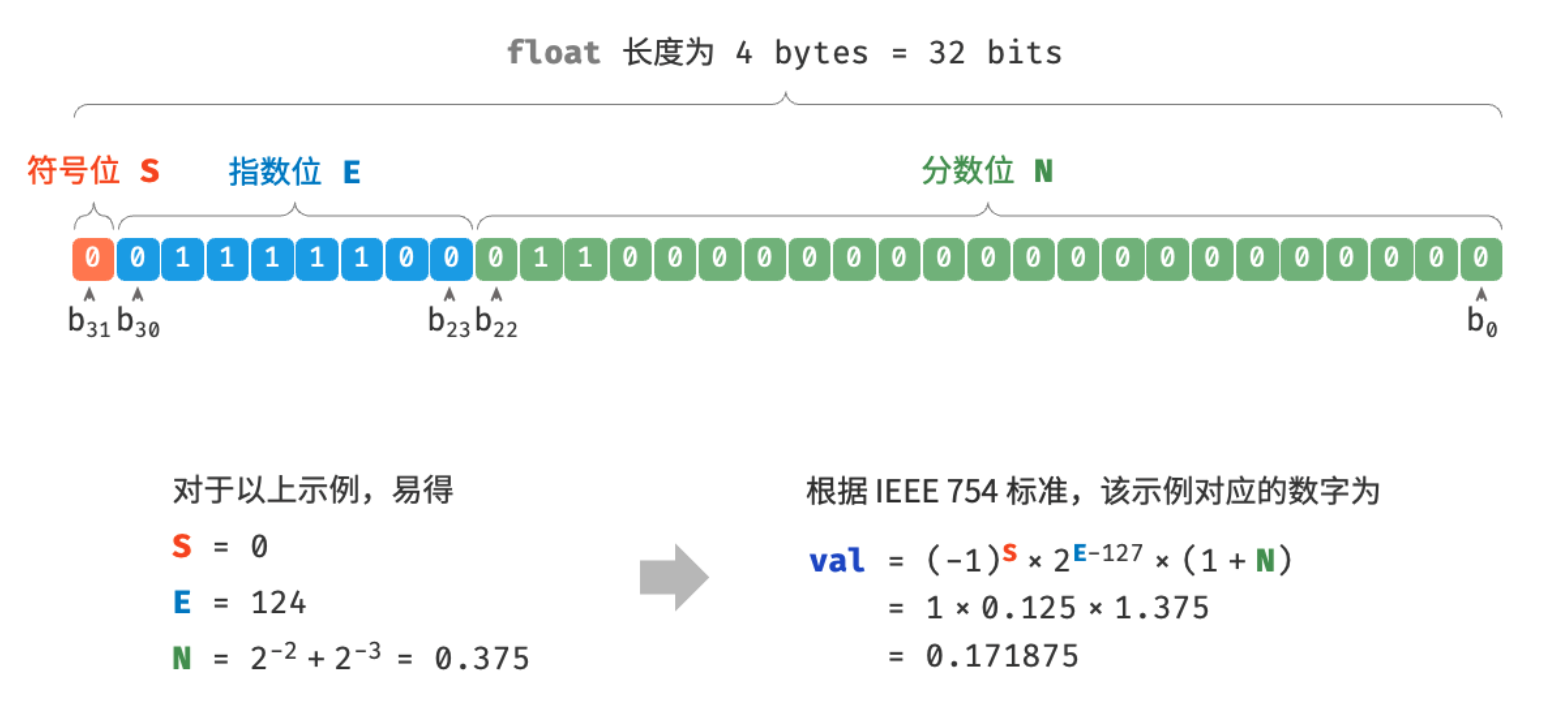
float的表示方式包含指数位,导致其取值范围远大于int,但需要明白的是,尽管浮点数float扩展了取值范围,但其副作用是牺牲了精度。同理,双精度double也采用了类似的表示方法。
字符编码
在计算机中,所有的数据都是以二进制的形式存储的,字符char也不例外,为了表示字符,需要建立一套字符集,用于规定每个字符和二进制数之间一一对应关系,有了字符集之后,计算机就可以通过查表完成二进制数到字符的转换了。
ASCII 字符集
ASCII码,其全称为American Standard Code for Information Interchange(美国标准信息交换代码):它使用7位2进制数(一个字节的低7位)表示一个字符,最多能够表示128个不同的字符。
最开始,ASCII码仅能表示英文,随着计算机的全球化,诞生了一种能够表示更多语言的 EASCII 字符集。它在 ASCII 的 7 位基础上扩展到 8 位,能够表示 256 个不同的字符。
GBK字符集
后来,EASCII 仍不够用。为处理数千日常汉字,我国于1980年推出了GB2312,收录6763字。后为兼容生僻字和繁体字,又扩展出GBK,收录21886字,并采用ASCII单字节、汉字双字节的编码方式。
Unicode字符集
Unicode的中文名称为“统一码”,是一种通用字符集,理论上能容纳100多万个字符,本质上是给每个字符分配一个编码,称为“码点”,它没有规定在计算机中如何存储这些字符码点,而是直接将所有的字符存储为等长的编码,由于ASCII已经证明了编码英文只需要1字符,这就使得英文在Unicode下编码非常浪费内存空间,为了解决这个问题,产生了下列的UTF-8编码。
UTF-8编码
UTF-8是当前使用最广泛的Unicode编码方法,它是一种可变长度的编码,使用1到4字节来表示一个字符,根据字符的复杂性而变,ASCII 字符只需 1 字节,拉丁字母和希腊字母需要 2 字节,常用的中文字符需要 3 字节,其他的一些生僻字符需要 4 字节。
UTF-8 的编码规则并不复杂,分为以下两种情况。
- 对于长度为 1 字节的字符,将最高位设置为0 ,其余 7 位设置为 Unicode 码点。值得注意的是,ASCII 字符在 Unicode 字符集中占据了前 128 个码点。也就是说,UTF-8 编码可以向下兼容 ASCII 码。这意味着我们可以使用 UTF-8 来解析年代久远的 ASCII 码文本。
- 对于长度为 n 字节的字符(其中 n > 1),将首个字节的高 n 位都设置为 1 ,第 n+1 位设置为 0 ;从第二个字节开始,将每个字节的高 2 位都设置为 10 ;其余所有位用于填充字符的 Unicode 码点。
UTF-8 之外,常见的编码还有 UTF-16 和 UTF-32。
- UTF-16:使用 2 或 4 字节表示字符。多数常用字符为 2 字节,且其编码值与 Unicode 码点相同。
- UTF-32:每个字符固定 4 字节,空间占用通常更大。
总结对比:
- 存储空间:UTF-8 对英文高效(1字节);UTF-16 对部分中文高效(2字节)。
- 兼容性:UTF-8 通用性最佳,是优先支持的标准。
编程语言的字符编码
早期编程语言常采用 UTF-16 或 UTF-32 等长编码存储字符串,便于像数组一样处理,具有以下优势:
- 随机访问:UTF-16 可直接访问第 nn 个字符,时间复杂度为 O(1)O(1);UTF-8 为变长编码,需要 O(n)O(n) 时间。
- 字符计数:UTF-16 获取字符串长度为 O(1)O(1) 操作,UTF-8 需遍历整个字符串。
- 字符串操作:在 UTF-16 上进行分割、连接、插入等操作更简单;UTF-8 需额外计算以避免编码错误。
现代语言的改进方案
- Python:str 类型根据最大 Unicode 码点动态选择存储:全 ASCII 用 1 字节,全在基本多语言平面(BMP)用 2 字节,有超出 BMP 的字符则用 4 字节。
- Go:string 内部使用 UTF-8,并提供
rune表示单个 Unicode 码点。

