初识spark
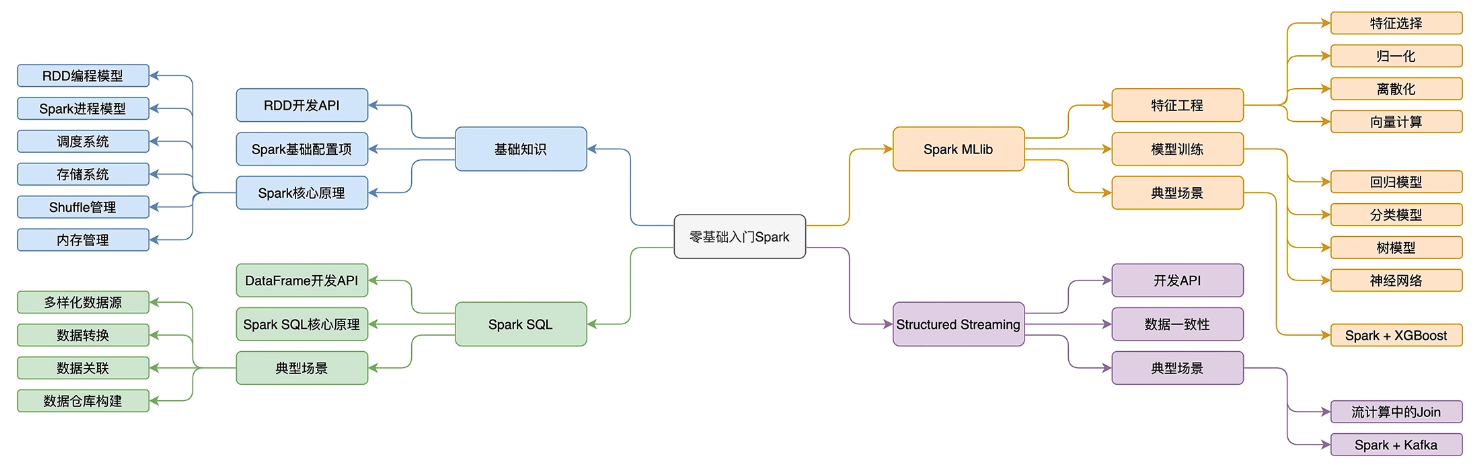
spark学习的知识图谱
spark的特点:
- 快:开发效率快,执行效率快。
- 支持多种开发语言,python/java/scala/R/SQL
- 提供丰富的开发算子:如RDD/DataFrame/Dataset
- 使用spark core和 spark sql 计算引擎
- 全:在计算场景的支持上非常全面。
- 批处理、流计算、数据分析、机器学习、图计算
spark和hadoop的关系
- 狭义上的hadoop:
- Hadoop特指HDFS、YARN、MapReduce这三个组件,他们分别是Hadoop分布式文件系统、分布式任务调度框架、分布式计算引擎。
- 广义上hadoop:
- Hadoop生态包含所有由这3个组件衍生出的大数据产品,如Hive、Hbase、Pig、Sqoop,等等。
- spark和hadoop的关联性:
- Spark和Hadoop的关系,是共生共赢的关系。
- Spark的定位是分布式计算引擎,因此,它的直接“竞争对手”,是MapReduce,也就是Hadoop的分布式计算引擎。
- Spark是内存计算引擎,而MapReduce在计算的过程中,需要频繁落盘,因此,一般来说,相比MapReduce,Spark在执行性能上,更胜一筹。
- 对于HDFS、YARN,Spark可与之完美结合,实际上,在很多的使用场景中,Spark的数据源往往存储于HDFS,而YARN是Spark重要的资源调度框架之一。
spark的安装
spark-shell 在运行的时候,依赖于 Java 和 Scala 语言环境
- 从Spark 官网下载安装包,选择最新的预编译版本即可;
- 解压 Spark 安装包到任意本地目录;
- 将
${解压目录}/bin配置到 PATH 环境变量。
入门Demo
import org.apache.spark.rdd.RDD
// 这里的下划线"_"是占位符,代表数据文件的根目录
val rootPath: String = _
val file: String = s"${rootPath}/wikiOfSpark.txt"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 打印词频最高的5个词汇
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)