spark中的RDD的属性和常用算子总结
内容预览
RDD的概念
RDD是构建Spark分布式内存计算引擎的基石,很多Spark的核心概念与核心组件都是衍生自RDD(如:DAG和调度系统)
虽然RDD API使用频率越来越低,绝大多数人也都已经习惯于DataFrame和Dataset API,但是,无论采用哪种开发语言或者API,你的应用在spark内部最终都会转化成RDD上的分布式计算
概念:
- RDD(Resilient Distributed Dataset)是一种抽象,是Spark对于分布式数据集的抽象,它用于囊括所有内存中和磁盘中的分布式数据实体。
类比理解:
可以把RDD类比为数组
| 对比项 | 数组 | RDD |
|---|---|---|
| 概念类型: | 数据结构实体 | 数据模型抽象 |
| 数据跨度: | 单机进程内 | 跨进程、跨计算节点 |
| 数据构成: | 数组元素 | 数据分片(Partitions) |
| 数据定位: | 数组下标、索引 | 数据分片索引 |
-
从三个维度类比RDD和数组
-
概念:数组是实体,��是一种存储同类元素的数据结构, 而RDD是一种抽象,囊括的是分布式计算环境中的分布式数据集。
-
活动范围:数组的活动范围很窄,仅限于单个计算节点的某个进程内,而RDD代表的数据集是跨进程、跨节点的,活动范围是整个集群。
-
数据定位:在数组中,承载数据的基本单元是元素,而RDD中承载数据的基本单元是数据分片。(在分布式计算环境中,一份完整的数据集,会按照某种规则切割成多份数据分片,这些数据分片被均匀地分发给集群内不同的计算节点和执行进程,从而实现分布式并行计算)
-
RDD的核心属性
属性列表:
- partitions: 数据分片
- Partitioner: 分片切割规则
- Dependencies: RDD依赖
- compute: 转换函数
属性之间的关系
-
数据分片的分布,是由 RDD 的 partitioner 决定的,RDD 的 partitions 属性,与它的 partitioner 属性是强相关的;
-
在数据形态的转换过程中,每个 RDD 都会通过 dependencies 属性来记录它所依赖的前一个、或是多个 RDD,简称“父 RDD”。与此同时,RDD 使用 compute 属性,来记录从父 RDD 到当前 RDD 的转换操作。
属性的理解
结合Word Count案例来进行理解rdd的核心属性
对于wordRDD而言,它的父RDD是lineRDD,它的dependencies属性记录的是lineRDD,从lineRDD到wordRDD的转换,其所依赖的操作是flatMap,因此,wordRDD的compute属性记录的是flatMap这个转换函数。
- RDD是spark对于分布式数据集的抽象,每一个RDD都代表这一种分布式数据形态。
- 比如 lineRDD,它表示数据在集群中以行(Line)的形式存在;而 wordRDD 则意味着数据的形态是单词,分布在计算集群中。
- RDD 到 RDD 之间的转换,本质上是数据形态上的转换(Transformations)。
RDD的编程模型
编程模型
-
在RDD的编程模型中,一共有两种算子:
- Transformations类算子: 定义并描述数据形态的转换过程
- Actions类算子: 将计算结果收集起来、或是物化到磁盘
-
Spark在运行时的计算被分为两个环节:
- 基于不同数据形态之间的转换, 构建计算流图(DAG, Directed Acyclic Graph)
- 通过Actions类算子,以回溯的方式触发并执行这个计算流图。
延迟计算

- 开发者调用的各类 Transformations 算子,并不立即执行计算,当且仅当开发者调用 Actions 算子时,之前调用的转换算子才会付诸执行。在业内,这样的计算模式有个专门的术语,叫作“延迟计算”(Lazy Evaluation)。
为什么action算子要设置成延迟计算吗?
严谨的说,不是要把action算子设置成延迟计算,而是Spark在实现上,选择了Lazy evaluation这种计算模式。
TensorFlow同样也采用了类似的计算模式。这种模式有什么好处、或者说收益呢?
我的理解是:优化空间。
和Eager evaluation不一样,lazy evaluation先构建计算图,等都构建完了,在付诸执行。这样一来,中间就可以打个时间差,引擎有足够的时间和空间,对用户代码做优化,从而让应用的执行性能在用户无感知的情况下,做到最好。
换个角度说,引擎选择lazy evaluation,其实是注重“用户体验”(开发者)的一种态度~
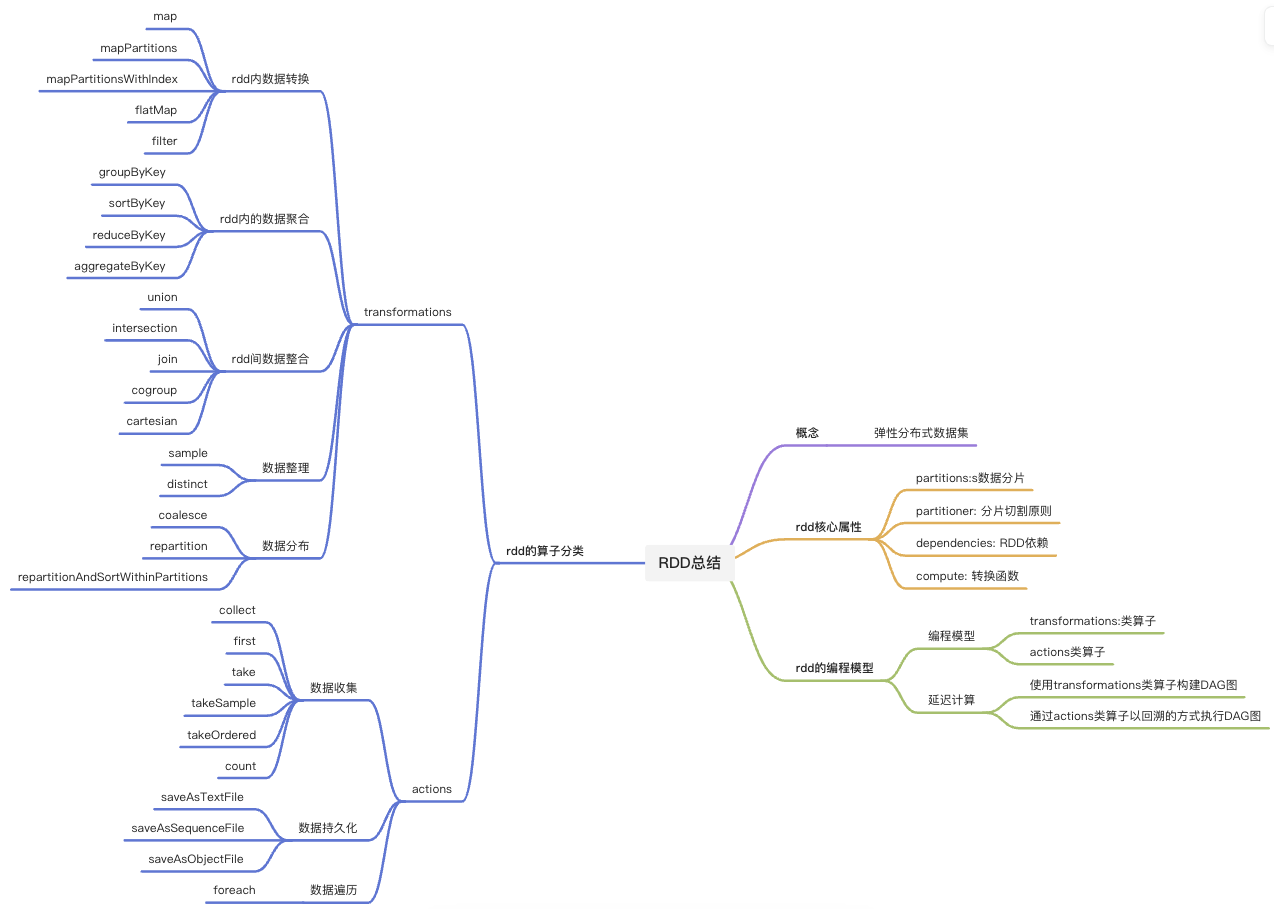
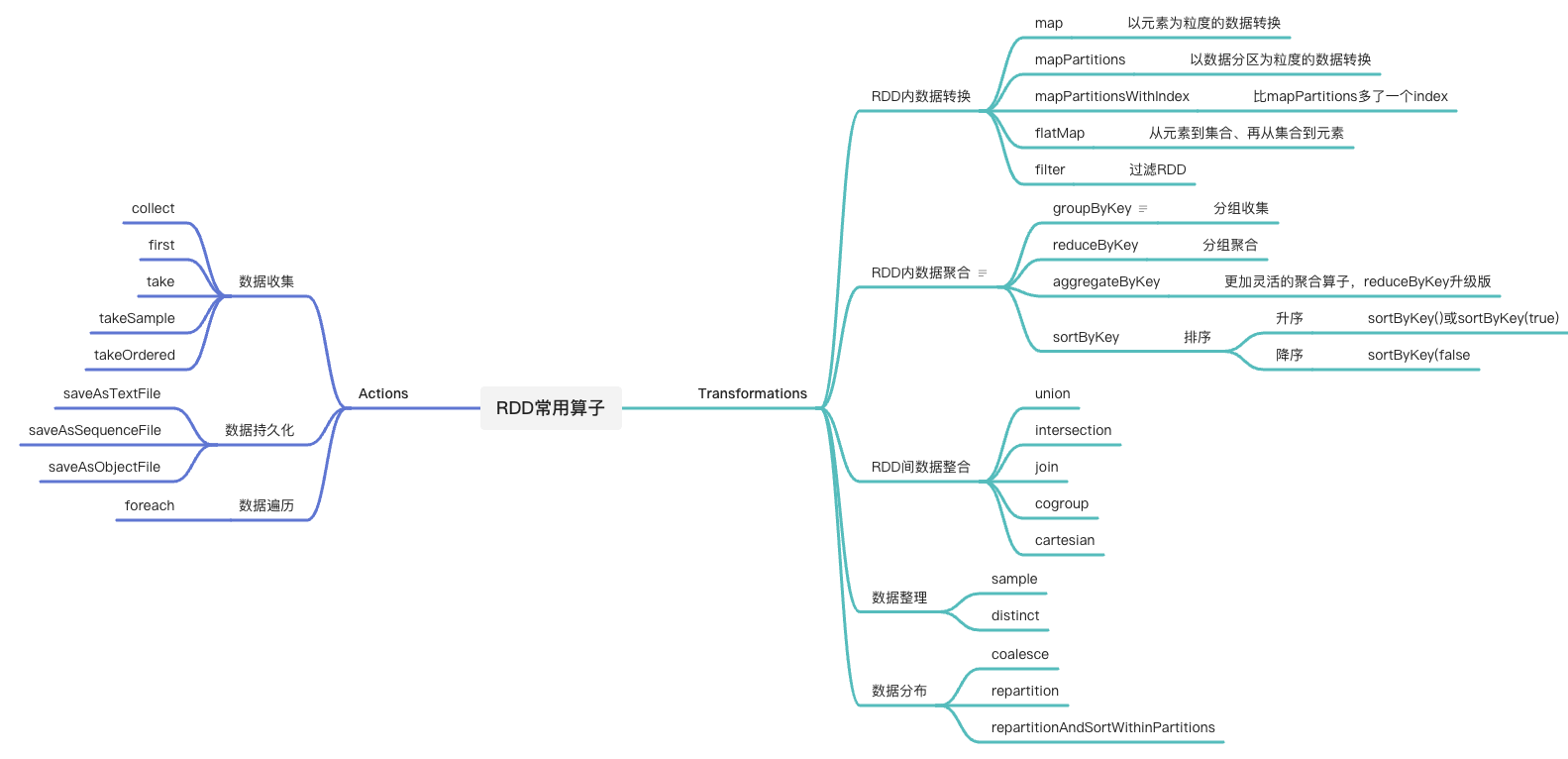
RDD的算子分类
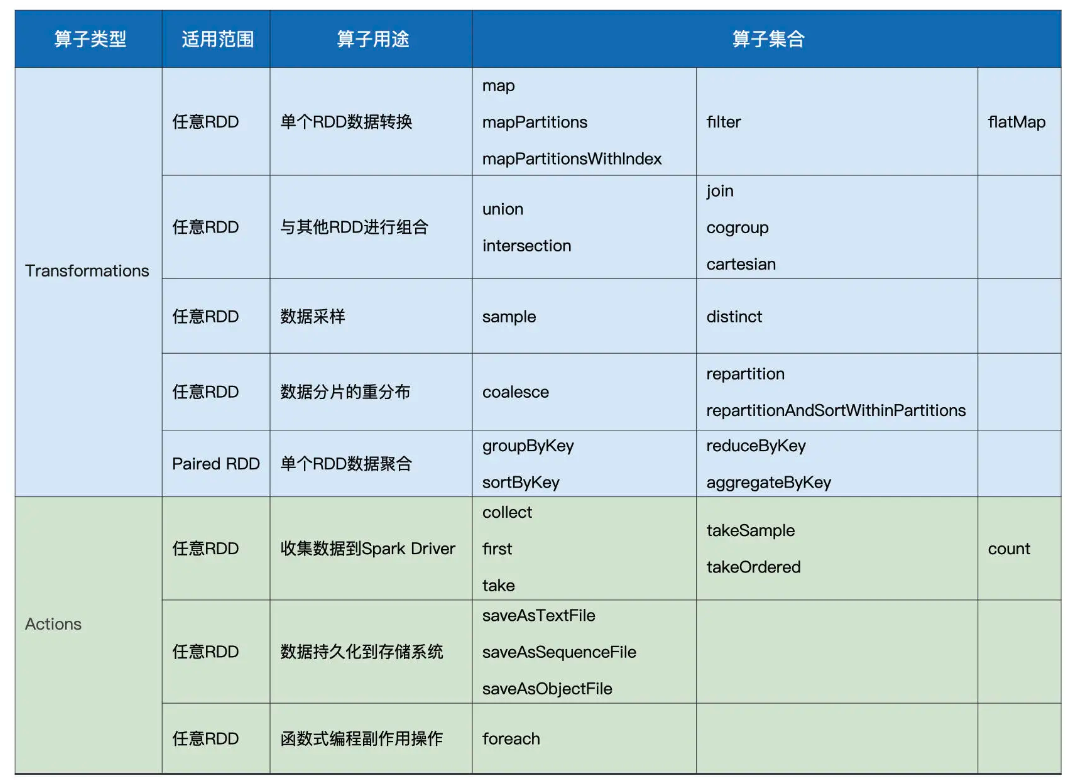
RDD的常用算子的操作
创建RDD
方式一:通过SparkContext.parallelize在内部数据之上创建RDD
-
内部数据是指:在spark应用中自定义的各类数据结构(数组、列表、映射等)
-
此方式只适用于小数据(原因:因为此方式数据集完全由Driver端创建,并且在创建完成后需要在全网范围内跨节点、跨进程地分发到其他Executors上,会带来极大的性能问题)
//parallelize create rdd demo
import org.apache.spark.rdd.RDD
val words: Array[String] = Array("Spark","is","cool")
val rdd: RDD[String] = sc.parallelize(words)
方式二:通过SparkContext.textFile等API从外部数据创建RDD
-
外部数据是指:本地文件系统、分布式文件系统或者其他大数据组件(Hive/Hbase/RDBMS等)的数据
// textFile create rdd demo
import org.apache.spark.rdd.RDD
val file: String = "./wikiOfSpark.txt"
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
RDD内的数据转换
- map: 以元素为粒度的数据转换
- mapPartitions: 以数据分区为粒度的数据转换
- flatMap: 从元素到集合、在从集合到元素
- filter: 过滤RDD
Note: 上述类型算子的操作不引入shuffle,(什么是shuffle可以见后面的笔记)
map: 以元素为粒度的数据转换
-
用法:
- 给定映射函数f,map(f)以元素为粒度对RDD做数据转换。其中f可以是带名函数,也可以是匿名函数,需要注意的是:它的形参类型必须与RDD的元素类型一致,而输出类型则可以任意定义。
-
特点:
- 允许开发者自由定义转换逻辑,比较灵活
- 在某些场景下,执行效率很低
-
demo:
//把普通RDD转换成Paired RDD : (Key,Value)对的RDD称为Paired RDD
//方式一:匿名函数demo
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// (word => (word, 1))就是f,=>左侧是输入形参,右侧是输出结果
//方式二:带名函数
//定义映射函数f
def f1(word: String): (String, Int) = {
return (word, 1)
}
def f2(word: String): (String,Int) = {
if (word.equals("Spark")){return (word, 2)}
return (word, 1)
}
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
varl kvRDD: RDD[String] = cleanWordRDD.map(f1)
varl kvRDD: RDD[String] = cleanWordRDD.map(f2)
mapPartitions: 以数据分区为粒度的数据转换
-
用法:
- 以数据分区为粒度,使用映射函数f对RDD进行数据转换。
-
应用场景
- 计算哈希值
- 数据记录共享
- 创建用于连接远端数据库的Connections对象
- 在线推理的机器学习模型
-
mapPartitions和map的区别:
-
demo
//把普通的RDD转换称为Paired RDD
import java.security.MessageDigest
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
val kvRDD: RDD[(String, Int)] = cleanWordRDD.mapPartitions{ partition =>
// 此处是以数据分区为粒度来获取MD5对象实例
val md5 = MessageDigest.getInstance("MD5")
val newPartition = partition.map(word => {
// 在处理每一条数据记录的时候,可以复用同一个Partition内的MD5对象
(md5.digest(word.getBytes).mkString, 1)
})
newPartition
}
//mapPartitions只需要实例化一次MD5对象,
//map算子却需要实例化多次,具体的次数则由分区内的数据记录的数量来决定的。
flatMap: 从元素到集合、再从集合到元素
-
用法:
在功能上和map以及mapPartitions一样,都是做数据映射的,只是映射的方式不同
- flatMap映射函数f的类型是(元素) => (集合),即元素到集合(数组、列表等),具体的映射逻辑分为两步
- 以元素为单位,创建集合
- 去掉集合的外包装,提取集合元素
- flatMap映射函数f的类型是(元素) => (集合),即元素到集合(数组、列表等),具体的映射逻辑分为两步
-
demo
由原来的统计单词的计数,改为统计相邻单词出现的次数

//读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
//以行为单位提取相邻单词
val wordPairedRDD: RDD[String] = lineRDD.flatMap(line => {
//将行转换为单词数组
val words: Array[String] = line.split(" ")
//将单个单词数组转换成相邻单词的数组
for (i <- 0 until words.length - 1) yield words(i) + "-" + words(i + 1)
})
- flatMap执行流程

filter:过滤RDD
-
用法:
- 作用:是对RDD进行过滤
- 原理:filter算子需要借助一个判定函数f,来实现对RDD的过滤转换。
- 判断函数:指类型为(RDD元素类型) => (Boolean)的函数,判断函数f的形参类型,必须与RDD的元素类型保持一致,而f的返回结果,只能是True或False.
- 说明:在任何一个RDD之上调用filter(f),其作用是保留RDD中满足f(f返回True)的数据元素,而过滤掉不满足f(f返回False)的数据元素
-
Demo:
//在上面 flatMap 例子的最后,得到了元素为相邻词汇对的 wordPairRDD,它包含的是像“Spark-is”、“is-cool”这样的字符串。
//为了仅保留有意义的词对元素,希望结合标点符号列表,对 wordPairRDD 进行过滤。
//例如,希望过滤掉像“Spark-&”、“|-data”这样的词对。
//定义特殊字符
val list: List[String] = List("&", "|", "#", "^","@")
//定义判断函数f
def f(s: String): Boolean = {
val words: Array[String] = s.split("_")
val b1: Boolean = list.contains(words(0))
val b2: Boolean = list.contains(words(1))
return !b1 && !b2 // 返回不在特殊字符列表中的词汇对
}
// 使用filter(f)对RDD进行过滤
val cleanPairRDD: RDD[String] = wordPairedRDD.filter(f)
RDD内的数据聚合
groupByKey: 分组收集
reduceByKey:分组聚合
aggregateByKey:reduceByKey的升级版
sortByKey: 排序
上述算子的操作会引入shuffle,同这些算子智能作用在Paired RDD上,(key, Value)键值对RDD
groupByKey: 分组收集
-
用法:
- 对key值相同的元素做分组,然后把相应的Value值,以集合的形式收集到一起;
- RDD[(Key, Value)] ---> RDD[(Key, Value集合)]
- groupByKey是无参数算子
- 由于性能原因(具体原因往下看),一般不常被使用
-
Demo
// 使用word count案例,将相同的单词收集到一起
import org.apache.spark.rdd.RDD
// 以行为单位做分词
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
//把普通RDD映射成Paired RDD
val kvRDD: RDD[(String, String)] = cleanWordRDD.map(word => (word, word))
//按照单词做分组收集
val words: RDD[(String, Iterable[String])] = kvRDD.groupByKey() -
groupByKey的执行流程:

- 为了完成测和功能分组收集,对于Key值相同、但分散在不同数据分区的原始数据记录,spark需要通过shuffle操作,跨节点、跨进程地把它们分发到相同的数据分区。
reduceByKey:分组聚合
-
用法:
- 根据聚合函数f给出的算法,把Key值相同的多个元素,聚合成一个元素。
- 给定RDD[(Key类型,Value类型)],聚合函数f的类型必须是:(Value类型,Value类型)=> (Value类型),简单的理解为:函数f的形参,必须是两个数值,且数值的类型必须与Value的类型相同,而f的返回值,也必须是Value的类型的数值。
-
Demo
//使用reduceByKey算子来计算同一个word当中最大的那个随机数,映射函数 word => (word, 1),而是改为 word => (word, 随机数)
import scala.util.Random._
//把RDD元素转换为(Key, Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, nextInt(100)))
//显示定义提取�最大值的聚合参数f
def f(x:Int, y:Int): Int = {
return math.max(x, y)
}
// 按照单词提取最大值
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey(f)
// 在 Map 阶段,以数据分区为单位,计算单词的加和;(sum)
// 而在 Reduce 阶段,对于同样的单词,取加和最大的那个数值;(max)- 算子(f):对于map来说,f是映射函数,对于filter来说,f是判定函数,对于reduceByKey,f是聚合函数
-
reduceByKey执行流程:

- 尽管 reduceByKey 也会引入 Shuffle,但相比 groupByKey 以全量原始数据记录的方式消耗磁盘与网络,reduceByKey 在落盘与分发之前,会先在 Shuffle 的 Map 阶段做初步的聚合计算。
- 相比 groupByKey,reduceByKey 通过在 Map 端大幅削减需要落盘与分发的数据量,往往能将执行效率提升至少一倍。
- reduceByKey 算子的局限性,在于其 Map 阶段与 Reduce 阶段的计算逻辑必须保持一致,这个计算逻辑统一由聚合函数 f 定义。当一种计算场景需要在两个阶段执行不同计算逻辑的时候,reduceByKey 就爱莫能助了。